Machine Learning
Machine Learning Journal
Support-Vector Networks
Read on February 25, 2024
Published 1995
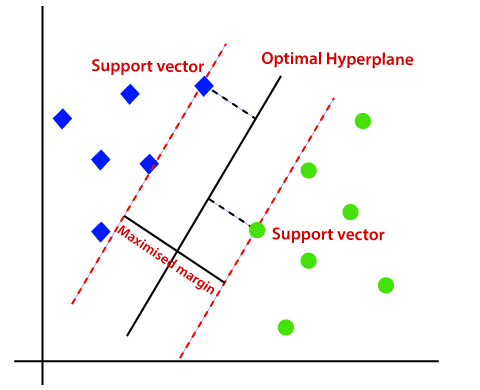
The 1995 paper Support-Vector Networks by Corinna Cortes and Vladimir Vapnik is widely regarded as one of the foundational works in modern machine learning. It introduced the concept of Support Vector Machines (SVM), an algorithm designed for classification and regression tasks, rooted in the principles of statistical learning theory. This paper marked a turning point in machine learning, laying a solid theoretical and practical foundation for supervised learning techniques. At its core, the paper describes a method to find the optimal hyperplane that separates classes of data in a high-dimensional space. The main goal is to maximize the margin, which is the distance between the hyperplane and the closest data points from each class. These critical data points are referred to as support vectors, as they define the decision boundary. By focusing only on the support vectors, SVM achieves computational efficiency and robust generalization, making it particularly effective for tasks with limited but high-dimensional datasets. A groundbreaking aspect of the paper was the introduction of the kernel trick. This mathematical technique allows SVM to work in higher-dimensional feature spaces without explicitly computing the transformations. Kernels, such as the polynomial kernel and the radial basis function (RBF), enable the algorithm to handle non-linear decision boundaries by implicitly mapping the data into a higher-dimensional space where a linear hyperplane can separate the classes. This innovation made SVM a versatile and powerful tool for a wide range of applications, from text classification to image recognition. Another significant contribution was the concept of soft margins, which introduced slack variables to allow some degree of misclassification. This approach accommodates datasets that are not perfectly separable, striking a balance between maximizing the margin and minimizing classification errors. The flexibility provided by the regularization parameter (C) allows practitioners to fine-tune the model based on the specific characteristics of their data. The impact of the Support-Vector Networks paper extends far beyond its theoretical contributions. SVM quickly gained traction as a go-to method for binary classification problems, particularly in scenarios where data is small and features are numerous. It has been successfully applied in diverse domains, including handwriting recognition, gene expression analysis, and even financial modeling. Reflecting on its importance, the paper highlights the power of combining mathematical rigor with practical insights. The use of convex optimization ensures that the SVM algorithm converges to a global minimum, providing reliable and interpretable results. Its emphasis on maximizing generalization rather than merely fitting the training data has made it a cornerstone in machine learning education and practice. In my own experience, SVM has been invaluable for tasks requiring robust and interpretable models. While the advent of deep learning has shifted attention towards neural networks, SVM remains a benchmark for classical machine learning techniques. It excels in scenarios where interpretability, computational efficiency, and performance on smaller datasets are critical. The principles established by Cortes and Vapnik continue to inspire advancements in machine learning, underscoring the enduring relevance of this seminal work.